
Machine Learning is a subset of artificial intelligence. It enables computers to learn from data and improve over time.
Machine Learning (ML) revolutionizes how we interact with technology. By leveraging algorithms, ML systems identify patterns and make data-driven decisions. Companies use ML for personalized recommendations, fraud detection, and predictive analytics. Healthcare, finance, and retail industries benefit from its applications, enhancing operational efficiency.
ML’s continuous learning capability helps businesses stay competitive. Understanding ML basics is crucial for anyone interested in technology. Learning about ML paves the way for innovation and smarter solutions.
➡️What is Machine Learning?
Machine learning is a branch of artificial intelligence that focuses on building systems capable of learning from data. These systems can make decisions and predictions without being explicitly programmed. Machine learning has grown rapidly in recent years, transforming industries and solving complex problems.
Basic Concepts
Understanding machine learning starts with some basic concepts. Data is the foundation of machine learning. Systems learn from large amounts of data to find patterns and make decisions.
- Algorithm: A set of rules or steps the machine follows to learn from data.
- Model: The result of the learning process. It’s what the algorithm produces after training on data.
- Training: The phase where the machine learns from data. The system adjusts its parameters to minimize errors.
- Testing: The phase where the trained model is tested on new, unseen data to evaluate its performance.
In addition, features are individual measurable properties or characteristics of the data. Features help the algorithm identify patterns. Labels are the outcomes or predictions we want the model to make.
Here’s a simple table to summarize these concepts:
| Term | Definition |
|---|---|
| Algorithm | A set of rules for learning from data. |
| Model | The output of the learning process. |
| Training | Phase where the machine learns from data. |
| Testing | Phase where model is evaluated on new data. |
| Features | Measurable properties of the data. |
| Labels | Outcomes we want the model to predict. |
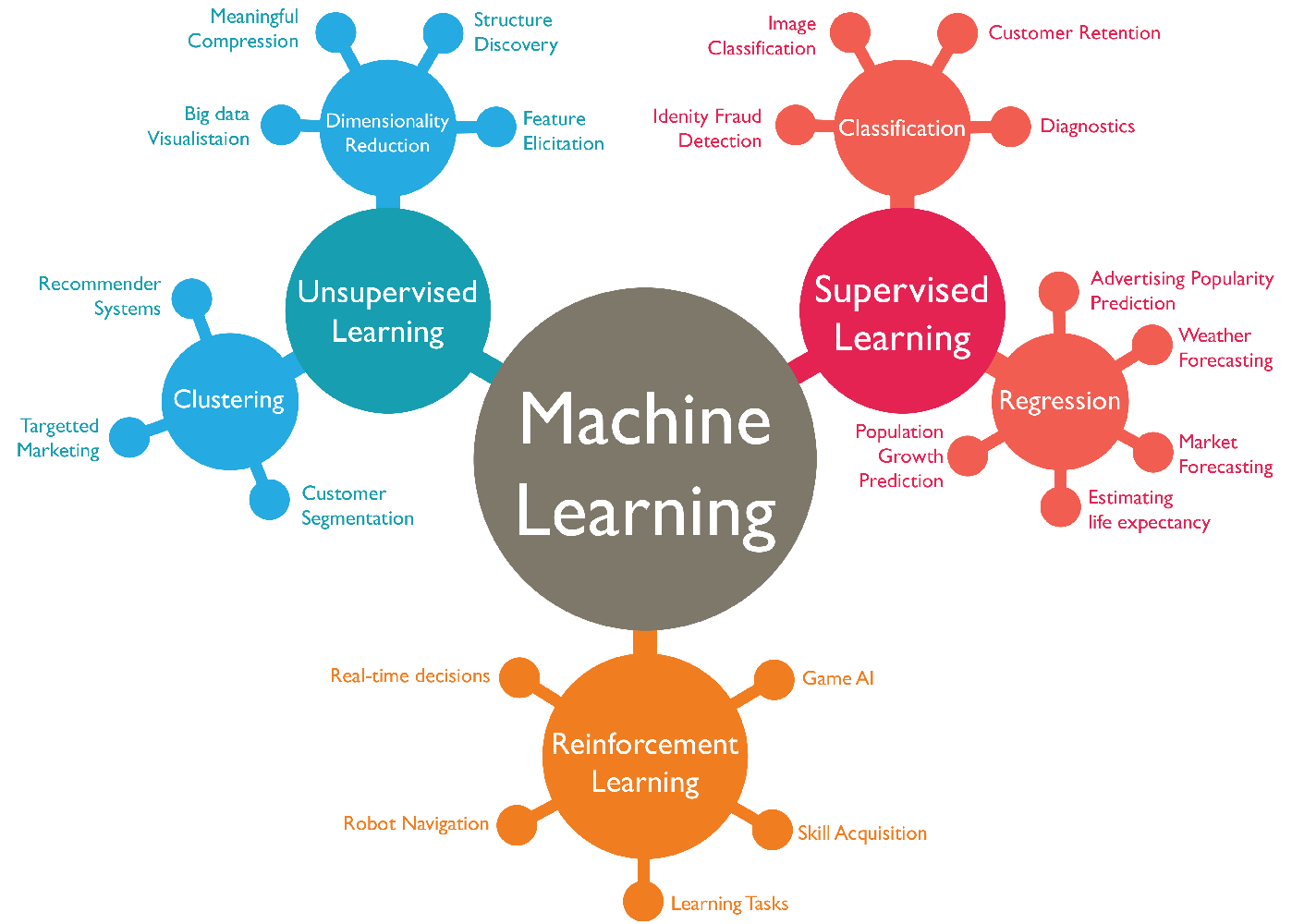
Types of Machine Learning
There are several types of machine learning, each with unique characteristics and applications.
- Supervised Learning: The machine learns from labeled data. It makes predictions based on input-output pairs. Examples include spam detection and image recognition.
- Unsupervised Learning: The machine learns from unlabeled data. It identifies patterns and structures in the data. Examples include customer segmentation and anomaly detection.
- Reinforcement Learning: The machine learns by interacting with an environment. It receives rewards or penalties based on its actions. Examples include game playing and robotic control.
Here’s a summary of these types:
| Type | Description | Examples |
|---|---|---|
| Supervised Learning | Learning from labeled data | Spam detection, image recognition |
| Unsupervised Learning | Learning from unlabeled data | Customer segmentation, anomaly detection |
| Reinforcement Learning | Learning by interaction | Game playing, robotic control |
Each type of machine learning serves different purposes and solves different problems. Understanding these types helps in selecting the right approach for a given task.
Credit: datascientest.com
➡️Key Algorithms
Machine Learning is transforming the way we interact with technology. It enables machines to learn from data and improve over time. Key Algorithms in Machine Learning are crucial for extracting patterns and making predictions. Let’s dive into the essential types of algorithms that drive this fascinating field.
Supervised Learning
Supervised Learning involves training a model on labeled data. This means the input data is paired with the correct output. The algorithm learns from this data, making predictions based on new, unseen data. Here are some common supervised learning algorithms:
- Linear Regression: Used for predicting continuous values. For example, predicting house prices.
- Logistic Regression: Used for binary classification problems. For example, determining if an email is spam or not.
- Decision Trees: A model that splits the data into branches to make predictions.
- Random Forest: An ensemble method that uses multiple decision trees to improve accuracy.
- Support Vector Machines (SVM): Used for classification and regression tasks. It finds the best boundary to separate different classes.
| Algorithm | Type | Use Case |
|---|---|---|
| Linear Regression | Regression | Predicting continuous values |
| Logistic Regression | Classification | Binary classification |
| Decision Trees | Classification/Regression | Various prediction tasks |
| Random Forest | Classification/Regression | Improving model accuracy |
| SVM | Classification/Regression | Finding class boundaries |
Unsupervised Learning
Unsupervised Learning deals with unlabeled data. The algorithm tries to find hidden patterns or intrinsic structures in the input data. This type of learning is useful for clustering and association tasks. Here are some common unsupervised learning algorithms:
- K-Means Clustering: Groups data into clusters based on similarities.
- Hierarchical Clustering: Builds a tree of clusters to understand data structure.
- Principal Component Analysis (PCA): Reduces data dimensions while retaining variance.
- Apriori Algorithm: Finds association rules in large datasets. For example, market basket analysis.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): Visualizes high-dimensional data in 2D or 3D space.
| Algorithm | Type | Use Case |
|---|---|---|
| K-Means Clustering | Clustering | Grouping similar data points |
| Hierarchical Clustering | Clustering | Building a tree of clusters |
| PCA | Dimensionality Reduction | Reducing data dimensions |
| Apriori Algorithm | Association Rule Learning | Market basket analysis |
| t-SNE | Visualization | Visualizing high-dimensional data |
Reinforcement Learning
Reinforcement Learning is about learning through trial and error. The algorithm learns by interacting with an environment. It receives feedback in the form of rewards or penalties. This type of learning is ideal for tasks that require a sequence of decisions. Common reinforcement learning algorithms include:
- Q-Learning: A value-based algorithm that seeks to find the best action to take given the current state.
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks to handle large state spaces.
- Policy Gradients: Directly optimizes the policy that defines the agent’s behavior.
- Actor-Critic Methods: Combines value-based and policy-based approaches for better performance.
- Monte Carlo Methods: Uses randomness to solve problems that might be deterministic in principle.
| Algorithm | Type | Use Case |
|---|---|---|
| Q-Learning | Value-based | Finding the best action |
| DQN | Value-based | Handling large state spaces |
| Policy Gradients | Policy-based | Optimizing agent behavior |
| Actor-Critic Methods | Hybrid | Improving performance |
| Monte Carlo Methods | Randomized | Solving deterministic problems |
➡️Applications in Industry
Machine Learning (ML) is transforming industries. It is changing the way we work and live. From healthcare to finance, ML is everywhere. It helps businesses improve efficiency and make better decisions.
Healthcare
Machine Learning has a massive impact on healthcare. It helps doctors and nurses deliver better care. Here are some key applications:
- Predictive Analytics: ML predicts patient outcomes. It helps in early diagnosis and treatment planning.
- Medical Imaging: ML analyzes X-rays and MRIs. It detects diseases like cancer at an early stage.
- Personalized Medicine: ML tailors treatments to individual patients. It considers their genetic makeup and lifestyle.
Below is a table showing ML applications in healthcare:
| Application | Benefits |
|---|---|
| Predictive Analytics | Early diagnosis, better outcomes |
| Medical Imaging | Accurate disease detection |
| Personalized Medicine | Tailored treatments |
Finance
Machine Learning is revolutionizing the finance sector. It helps in fraud detection and risk management. Here are some important applications:
- Fraud Detection: ML spots unusual transactions. It reduces the risk of fraud.
- Risk Management: ML assesses credit risk. It helps banks decide who to lend money to.
- Algorithmic Trading: ML analyzes market data. It makes trading decisions in real-time.
Below is a table showing ML applications in finance:
| Application | Benefits |
|---|---|
| Fraud Detection | Reduced fraud risk |
| Risk Management | Better lending decisions |
| Algorithmic Trading | Real-time trading decisions |
Retail
Machine Learning is transforming the retail industry. It helps in inventory management and customer experience. Here are some key applications:
- Inventory Management: ML predicts demand. It helps retailers stock the right products.
- Customer Experience: ML personalizes shopping experiences. It suggests products based on customer behavior.
- Pricing Optimization: ML sets optimal prices. It maximizes sales and profits.
Below is a table showing ML applications in retail:
| Application | Benefits |
|---|---|
| Inventory Management | Right product stocking |
| Customer Experience | Personalized shopping |
| Pricing Optimization | Maximized sales and profits |
➡️Data Requirements
Machine Learning is revolutionizing industries by enabling computers to learn from data. Data Requirements are crucial for successful Machine Learning projects. The quality and quantity of data directly impact the model’s performance. Understanding data requirements helps ensure reliable and accurate results.
Data Collection
Data Collection is the first step in a Machine Learning project. Collecting the right data is essential for training effective models. Here are some key points to consider:
- Data Sources: Identify various data sources such as databases, online repositories, and APIs.
- Data Volume: Ensure you collect a sufficient amount of data to train robust models. More data often leads to better performance.
- Data Variety: Gather diverse data types, including text, images, and numerical data, to improve model generalization.
- Data Quality: High-quality data is free from errors, duplicates, and inconsistencies. Poor quality data can lead to inaccurate models.
Consider using the following methods for data collection:
| Method | Description |
|---|---|
| Web Scraping | Extracting data from websites using automated scripts. |
| APIs | Accessing data from online services and platforms. |
| Surveys | Collecting data directly from users through questionnaires. |
| Databases | Using existing databases to gather structured data. |
Data Preprocessing
Data Preprocessing prepares raw data for training. It involves cleaning, transforming, and organizing data. Key steps include:
- Data Cleaning: Remove noise, correct errors, and handle missing values. This step ensures data quality.
- Data Normalization: Scale features to a similar range. This helps models converge faster.
- Data Transformation: Convert categorical data into numerical formats. Use techniques like one-hot encoding.
- Data Splitting: Divide data into training, validation, and test sets. This helps evaluate model performance.
Let’s look at common techniques used in data preprocessing:
| Technique | Description |
|---|---|
| Normalization | Scaling data to a 0-1 range. |
| Standardization | Transforming data to have a mean of 0 and a standard deviation of 1. |
| One-Hot Encoding | Converting categorical variables into binary vectors. |
| Imputation | Filling in missing values using statistical methods. |
Effective data preprocessing ensures that the model learns from accurate and relevant data, leading to better performance and reliability.
➡️Challenges And Limitations
Machine Learning has revolutionized various industries by enabling computers to learn from data. Despite its potential, Machine Learning faces several challenges and limitations. These issues can affect the accuracy, fairness, and reliability of the models. Let’s explore some of the key challenges and limitations of Machine Learning.
Overfitting
Overfitting is a common problem in Machine Learning. It occurs when a model learns the training data too well. This causes the model to perform poorly on new, unseen data. Overfitting can make a model very accurate on training data but inaccurate on test data.
Here are some signs of overfitting:
- High accuracy on training data but low accuracy on test data.
- Complex models with many parameters.
- Model captures noise instead of the actual pattern.
To prevent overfitting, consider the following methods:
- Cross-validation: Split the data into multiple parts and train the model on each part.
- Pruning: Remove some parts of the model that are not necessary.
- Regularization: Add a penalty for large coefficients in the model.
- Early stopping: Stop training when the model’s performance on a validation set starts to deteriorate.
Overfitting remains a significant challenge. Proper techniques and methods can mitigate its effects.
Bias And Fairness
Bias in Machine Learning occurs when the model favors certain groups over others. This can lead to unfair outcomes and discrimination. Bias can arise from various sources, including the data, the model, or the human designers.
Common sources of bias include:
- Data Collection: The data may not represent all groups equally.
- Labeling: The labels may reflect human prejudices.
- Feature Selection: The chosen features may be biased.
Addressing bias is crucial for ensuring fairness in Machine Learning models. Here are some methods to achieve fairness:
- Balanced Data: Ensure the data represents all groups fairly.
- Fair Algorithms: Use algorithms designed to minimize bias.
- Regular Audits: Regularly check models for bias and correct them.
- Transparency: Make the decision-making process transparent.
Bias and fairness are critical for ethical Machine Learning. They ensure that models serve everyone equally and justly.
➡️Tools And Frameworks
Machine Learning is transforming industries by enabling computers to learn from data and make decisions. To harness its potential, various tools and frameworks have emerged. These resources simplify complex tasks and make Machine Learning accessible to everyone.
Popular Libraries
Several popular libraries are essential for Machine Learning tasks. These libraries provide pre-built functions and models, saving you time and effort. Here are some of the most widely used libraries:
- TensorFlow: Developed by Google, TensorFlow is one of the most popular Machine Learning libraries. It is known for its flexibility and scalability. It supports both deep learning and traditional Machine Learning models.
- Scikit-Learn: This library is perfect for beginners. It is built on NumPy, SciPy, and Matplotlib. Scikit-Learn offers simple and efficient tools for data mining and data analysis.
- PyTorch: Developed by Facebook, PyTorch is gaining popularity for its ease of use and dynamic computation graph. It is widely used in research and production environments.
- Keras: Keras is an open-source software library that provides a Python interface for artificial neural networks. It acts as an interface for the TensorFlow library.
Here is a comparison table for these libraries:
| Library | Developed By | Key Features |
|---|---|---|
| TensorFlow | Flexibility, Scalability, Supports deep learning | |
| Scikit-Learn | Community-driven | Easy to use, Efficient, Good for beginners |
| PyTorch | Dynamic computation graph, Research-friendly | |
| Keras | Community-driven | User-friendly, High-level API |
Development Environments
Choosing the right development environment is crucial for effective Machine Learning projects. These environments provide tools and interfaces for coding, testing, and debugging. Here are some popular development environments:
- Jupyter Notebook: Jupyter is a web-based interactive development environment. It supports over 40 programming languages, including Python. It is ideal for data cleaning, transformation, visualization, and statistical modeling.
- Google Colab: Google Colab is a free cloud service. It supports Jupyter notebooks and provides free access to GPUs. It is perfect for large-scale Machine Learning projects.
- PyCharm: PyCharm is an integrated development environment for Python. It provides code analysis, a graphical debugger, an integrated unit tester, and supports web development with Django.
- Spyder: Spyder is an open-source IDE for scientific programming in Python. It is designed for data scientists and engineers. It features a unique combination of advanced editing, analysis, debugging, and profiling functionality.
Here is a brief comparison of these development environments:
| Environment | Key Features | Best For |
|---|---|---|
| Jupyter Notebook | Interactive, Supports many languages, Visualization | Data analysis, Prototyping |
| Google Colab | Cloud-based, Free GPUs, Jupyter support | Large-scale projects, Collaboration |
| PyCharm | Code analysis, Debugging, Web development | Professional development, Integrated tools |
| Spyder | Scientific programming, Debugging, Profiling | Data science, Engineering |
➡️Future Trends
Machine Learning is evolving rapidly. Future trends in this field promise to revolutionize industries and daily life. With advancements in AI, ethical considerations, and integration with other technologies, the potential is limitless.
Ai Integration
AI Integration is one of the most exciting future trends in machine learning. As AI becomes more advanced, its integration into various sectors will increase. This will create smarter systems and more efficient processes.
Here are some areas where AI integration will play a significant role:
- Healthcare: AI will help diagnose diseases faster and more accurately.
- Finance: AI-driven analytics will improve investment strategies and risk management.
- Transportation: Self-driving cars and smart traffic systems will make travel safer and more efficient.
- Retail: Personalized shopping experiences and inventory management will enhance customer satisfaction.
In the near future, AI will also integrate with Internet of Things (IoT) devices, creating smart homes and cities. For example, AI can optimize energy usage in smart homes, reducing costs and environmental impact.
The table below shows the potential benefits of AI integration:
| Sector | AI Integration Benefits |
|---|---|
| Healthcare | Faster, accurate diagnoses; personalized treatment plans |
| Finance | Improved investment strategies; better risk management |
| Transportation | Safer travel; efficient traffic management |
| Retail | Personalized shopping; better inventory management |
Ethical Considerations
As machine learning and AI technologies advance, ethical considerations become crucial. Ensuring AI systems are fair, transparent, and accountable is essential for gaining public trust.
Key ethical concerns include:
- Bias and Fairness: AI systems must avoid biases that can lead to unfair treatment of individuals or groups.
- Transparency: AI decision-making processes should be understandable and explainable.
- Privacy: Protecting user data and ensuring privacy is paramount in AI applications.
- Accountability: Clear guidelines on who is responsible for AI decisions are needed.
Addressing these ethical concerns requires collaboration between tech developers, policymakers, and society. By creating ethical guidelines and frameworks, we can ensure AI benefits everyone.
Importance of Ethical AI:
- Builds public trust in AI systems
- Ensures fair treatment of all individuals
- Protects user privacy and data
- Promotes responsible AI development and use
In summary, the future of machine learning is bright with AI integration and ethical considerations at the forefront. These trends will shape a more intelligent, efficient, and fair world.
Credit: www.wordstream.com
➡️Getting Started
Machine Learning is a fascinating field that allows computers to learn from data. It has applications in various domains like healthcare, finance, and entertainment. If you are a beginner, you might wonder how to get started with Machine Learning. This guide will help you with essential resources and practical projects to kickstart your journey.
Learning Resources
Diving into Machine Learning can be overwhelming. But with the right resources, you can make the process smooth and enjoyable. Here are some valuable resources to get you started:
- Online Courses: Websites like Coursera, Udemy, and edX offer beginner to advanced-level courses. Some popular courses include Andrew Ng’s Machine Learning course on Coursera and Machine Learning A-Z on Udemy.
- Books: Books like “Hands-On Machine Learning with Scikit-Learn and TensorFlow” by Aurélien Géron and “Pattern Recognition and Machine Learning” by Christopher Bishop are excellent for in-depth learning.
- Blogs and Websites: Websites like Towards Data Science, Machine Learning Mastery, and KDnuggets provide a wealth of articles, tutorials, and guides.
- YouTube Channels: Channels like 3Blue1Brown, StatQuest, and Sentdex offer explanatory videos that break down complex topics into easy-to-understand concepts.
Here is a table summarizing some essential resources:
| Resource Type | Example | Description |
|---|---|---|
| Online Course | Andrew Ng’s Machine Learning | Comprehensive Introduction to Machine Learning |
| Book | Hands-On Machine Learning | Practical guide using Scikit-Learn and TensorFlow |
| Blog | Machine Learning Mastery | Tutorials and guides on various ML topics |
| YouTube Channel | 3Blue1Brown | Visual explanations of complex math and ML concepts |
Practical Projects
Working on practical projects is crucial for understanding Machine Learning concepts. Here are some simple projects to start with:
- Predicting House Prices: Use datasets like the Boston Housing dataset to predict house prices based on features like location, size, and number of rooms.
- Image Classification: Use the CIFAR-10 or MNIST datasets to classify images into categories. This project helps you understand convolutional neural networks (CNNs).
- Sentiment Analysis: Analyze the sentiment of text data, such as movie reviews, using natural language processing (NLP) techniques.
- Stock Price Prediction: Use historical stock price data to predict future prices. This project involves time series analysis and regression techniques.
Here’s a brief description of the projects:
| Project | Description | Skills Learned |
|---|---|---|
| Predicting House Prices | Predict house prices using features like location and size. | Regression, Feature Engineering |
| Image Classification | Classify images into categories using CNNs. | Deep Learning, CNNs |
| Sentiment Analysis | Analyze text data to determine sentiment. | NLP, Text Processing |
| Stock Price Prediction | Predict future stock prices using historical data. | Time Series Analysis, Regression |
These projects will give you hands-on experience and build your confidence in applying Machine Learning techniques.

Credit: www.spiceworks.com
➡️Frequently Asked Questions
- What Is Machine Learning?
Machine Learning is a subset of AI. It allows systems to learn and improve from experience. Algorithms analyze data to make predictions or decisions without explicit programming.
- How Does Machine Learning Work?
Machine Learning works by using algorithms to process data. It identifies patterns and makes predictions. The model improves over time with more data.
- Why Is Machine Learning Important?
Machine Learning is important because it automates decision-making. It enhances accuracy and efficiency in various applications. This includes healthcare, finance, and marketing.
- What Are the Types Of Machine Learning?
The main types of Machine Learning are supervised, unsupervised, and reinforcement learning. Each type serves different purposes and applications.
➡️Final Thought
Machine learning is transforming industries and daily life. Embrace its potential to stay ahead in a competitive world. Keep learning and adapting to harness its full power. Remember, the future belongs to those who innovate. Stay curious and explore the endless possibilities machine learning offers.


